Not Another Sunday: Building a 137K-Listing Coffee Directory
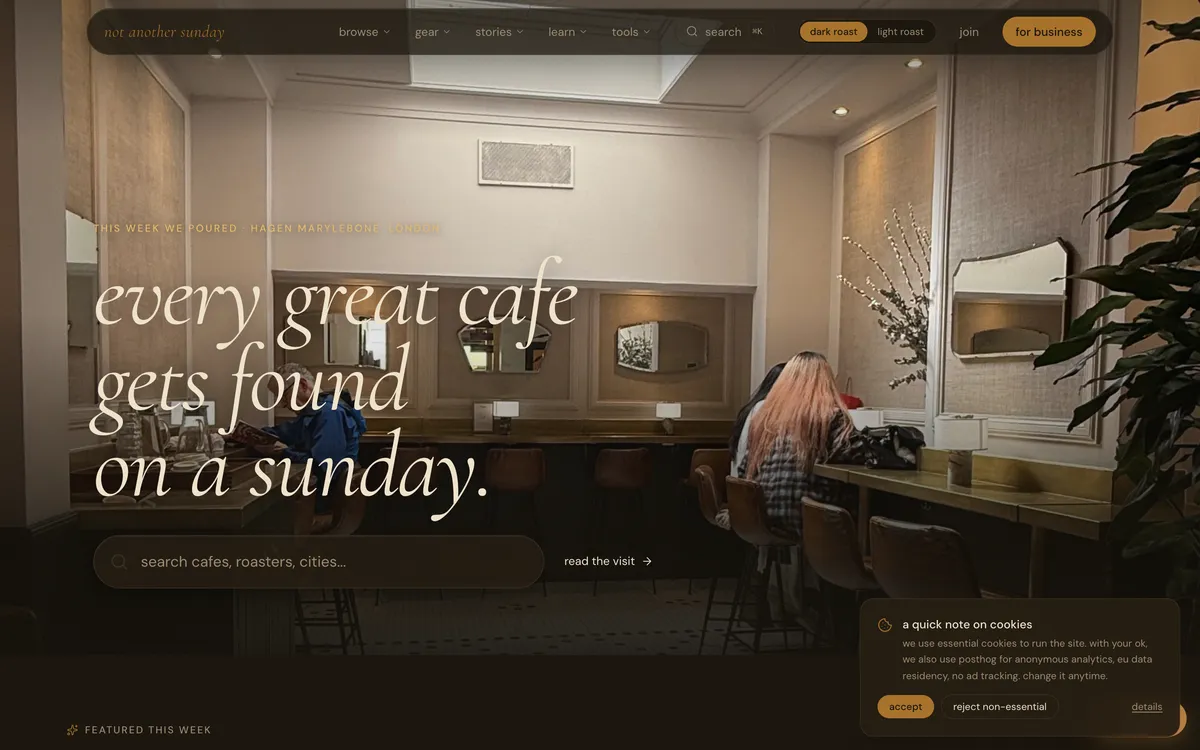
Not Another Sunday is a global directory of specialty coffee shops, pubs and restaurants -- 137,000+ venue listings ranked by a custom quality score instead of review count -- and it is our own product, built and run entirely in-house at Social Animal. The core move was designing a scoring system (the NRI) that rewards genuine quality over tourist volume, then feeding that data into a programmatic SEO engine that generates hundreds of editorial landing pages from a single template.
This is the story of the hard calls behind it.
Why review-count ranking is broken
Search for the best coffee in almost any major city and Google will surface the same chain cafe sitting next to a train station. It has 4,200 reviews because every commuter and tourist walks past it. Rating is fine -- 4.1 stars -- but the espresso tastes like burned rubber.
Three blocks away, a roaster is pulling shots from single-origin beans sourced directly from a farm in Huila. 180 reviews, all glowing, from people who made a deliberate trip to get there. Google buries it on page two.
I have seen this pattern in city after city and it is not a quirk. It is structural. Review volume is a proxy for foot traffic, full stop, and generic directories inherit that bias wholesale -- they pull star ratings straight from Google, sort by count, and call it a recommendation. They also go stale fast, padding lists with bakeries, breweries and restaurants that happen to serve coffee as an afterthought.
I wanted a directory that could tell the difference between a genuine specialty roaster and a tourist trap. That meant building the scoring system myself, from scratch, and defending every decision in it.
The NRI score and the filtering decisions
The data foundation is 137K listings harvested and enriched from Google Places and DataForSEO. But raw data is not a directory. The first filtering pass uses Google's business category to classify each venue: is this a specialty coffee shop, a restaurant that also serves coffee, a bakery, a brewery? Restaurants, bakeries and tourist-oriented venues get filtered OUT of the specialty rankings entirely.
Category alone is not enough, though. A place can be categorized as a "coffee shop" and still serve Lavazza from a superautomatic. So I added a language-model review pass that reads through a venue's reviews looking for specialty signals -- mentions of single origin, pour-over, roasting in-house, specific farms or processes -- versus generic food-first language. The combination of structured category data and unstructured review analysis gives a classification I trust enough to stake the product on.
Then comes the NRI score itself, a 0-100 composite that blends four factors:
- Bayesian-adjusted rating -- raw star average pulled toward a global mean so a 5.0 from 3 reviews does not beat a 4.7 from 500.
- Review volume on a log curve -- volume matters, but with diminishing returns. Going from 50 to 200 reviews moves the needle. Going from 2,000 to 4,000 barely does.
- Specialty weighting -- the classification confidence from the pipeline above. Venues identified as genuine specialty get a boost.
- Local-versus-tourist credibility factor -- heuristics around review patterns that separate devoted-regular signals from tourist-passing-through signals.
The result: a quiet neighborhood roaster with 200 devoted regulars can outrank a 4,000-review tourist magnet. This one decision shapes every leaderboard on the site. It is the reason the product exists, and it is the thing I defend most carefully as the dataset grows. People push back on it -- venue owners whose rankings drop, partners who want to weight recency differently -- and my answer is always the same: the score exists to be right, not to be popular.
Programmatic SEO from a single renderer
With 137K scored and classified venues, the obvious next step is pages people actually search for. I built an editorial page engine that generates ranked lists: "best coffee in {city}", "{origin} roasters in {city}", neighborhood pages, landmark pages, drink-specific and amenity-specific pages. Hundreds are live.
Every page is rendered from a single Next.js template. The data drives the content -- ranked venues, NRI scores, editorial descriptions, structured data, internal links -- but the template handles layout, schema markup and routing. This is the same pattern I wrote about in our programmatic SEO case study covering 253,000 pages, applied here with tighter editorial gates.
Those gates matter and I will not apologize for how strict they are. Every generated description passes hard quality checks: minimum word count, a banned-vocabulary list (no filler phrases, no generic praise), and an AI-detection scoring pass. Venues that deserve deeper coverage get first-person in-person reviews -- 1,500+ words, researched and fact-checked. The goal is that no page on the site feels like it was spit out by a content mill, even though the underlying system is fully automated.
The engineering runs on Next.js App Router with static generation and per-page revalidation across all 137K routes. Supabase handles the Postgres database and storage layer. Vercel hosts the front end. Tailwind CSS v4 keeps styling consistent. The architecture is tuned to stay fast and cheap at this scale -- the same stack I would recommend for any large-scale directory build.
The coffees layer
A coffee directory that only lists shops felt incomplete to me from the start. I wanted to catalog the coffees themselves. So I built crawlers that scrape roaster shopfronts across Shopify, WooCommerce and other e-commerce platforms, pulling product data for individual coffees: origin country, region, farm, process method, tasting notes, price.
10,500+ individual coffees are now cataloged, each on its own page, each linked back to the roaster that sells it. Roasters from 60+ countries are represented. This layer turns Not Another Sunday from a "where to go" directory into a "what to drink" reference -- and it creates thousands of additional long-tail pages with genuine informational value. When someone searches for a specific Ethiopian natural process coffee and lands on a page that actually tells them something useful, that is the product working the way I designed it to.
The indexation call that made it work
This was the hardest and most counterintuitive decision I made. With 137K listings in the database, the naive approach is to put them all in the sitemap and let Google sort it out. I tried that first. The sitemap ballooned to 132K URLs, and Google's response was predictable: it crawled slowly, indexed erratically, and treated the bulk of pages as low-value.
So I did the opposite. I pulled thin listings OUT of the index. Any venue that had not earned real content -- a meaningful description, enough data to differentiate it, photos -- got a noindex tag and was removed from the sitemap. The sitemap shrank from 132K to 55K quality URLs.
The results were immediate. 84% of submitted listings are now indexable, up from a sitemap bloated with thin pages that Google largely ignored. Crawl budget concentrated on pages that actually deserve to rank. The remaining thin pages still exist on the site for internal linking and user navigation, but they do not compete for crawl attention.
Holding pages back from the index is the call most directory builders get wrong. I understand the instinct -- more pages, more chances to rank, more surface area. It is wrong. Google does not reward volume, it rewards signal density. A 55K-page site where every page earns its place outperforms a 132K-page site where half the pages are stubs. I wrote about this dynamic in the Florida Massage Elite case study as well, but Not Another Sunday is where I proved it at the largest scale.
Place-ID-matched photo seeding keeps listings visual. Every image is re-encoded to WebP to keep page weight down. The classification pipeline -- Google category plus coordinate-matched place IDs plus the language-model QA pass -- runs continuously to keep rankings clean as new venues enter the dataset.
The growth loop
A directory is only as valuable as its freshness. The growth loop for Not Another Sunday works like this: venue owners can claim their profile for free and earn a trust badge that signals verified status to visitors. A two-channel outreach system -- cold email plus a warmer editorial invite -- brings roasters in. Per-recipient dedup and suppression run end to end so nobody gets contacted twice.
Claimed profiles give owners a reason to keep their data current, which keeps the directory fresh, which keeps pages ranking, which brings more owners in. It is a flywheel, not a campaign. The distinction matters because campaigns end.
What I would do differently
I underestimated how much editorial work the coffees layer would require. Crawled product data from roaster sites is messy -- inconsistent field names, tasting notes that are sometimes marketing copy and sometimes genuine cupping descriptors. Cleaning that data at scale is an ongoing cost I should have budgeted for from day one. I knew it would be imperfect. I did not know how imperfect, or how much that would compound at 10,000-plus SKUs.
I also waited too long to implement the indexation cut. The first three months of the project had a bloated sitemap that trained Google to see the domain as low-quality. Recovering from that took patience -- more than I had expected, and more than I would want a client to absorb.
But the NRI score -- the decision to rank by quality instead of volume -- is the call I would make again every time. It is the reason the product has integrity, and integrity is the only moat a directory can have.
FAQ
How does the NRI score work and why not just use raw ratings?
The NRI blends a Bayesian-adjusted star rating, review volume on a logarithmic curve, a specialty classification weight, and a local-versus-tourist credibility factor into a 0-100 score. Raw ratings reward volume and penalize small venues -- the NRI corrects for that so genuinely great roasters surface above tourist traps.
How does a directory with 137K listings stay fast on Next.js?
Static generation with per-page revalidation means pages are pre-built and served from Vercel's edge, then refreshed on a schedule. Supabase handles data queries efficiently, images are re-encoded to WebP, and only the pages that need regeneration get rebuilt -- so the site stays fast without redeploying 137K routes at once.
Why did you deliberately deindex thin pages?
Google treated a 132K-URL sitemap mostly as noise. Cutting it to 55K quality URLs concentrated crawl budget on pages with real content and differentiation. The thin listings still exist for internal linking, but keeping them out of the index raised indexability to 84% and improved ranking signals across the board.
How was the coffee catalog built?
Crawlers scrape roaster shopfronts on Shopify, WooCommerce and other platforms, extracting origin, process, tasting notes and pricing for each product. The data is cleaned and normalized, then each of the 10,500+ coffees gets its own page linked back to the roaster. Ongoing re-crawls keep the catalog current.
Do you build directories like this for other companies?
Yes. The architecture behind Not Another Sunday -- programmatic SEO, quality scoring, scalable Next.js rendering -- is the same stack we deploy for clients through our directory development practice. Not Another Sunday is where we test every pattern before recommending it.